Google's search tricks: using index of, intitle and more
Published on March 30,2017

In this article, I will walk you through some search tricks (on Google engine) that can help you delve into your research faster, often getting the intended information. The article is categorized into three sections. In the first section, you will learn about the basic searches and the most commonly used methods. In the second part, you will learn about more advanced operators that help dedicate your searches to a niche technique. in the last part, you will be presented with a few hacker tips.
Table of contents
Basic search techniques
Simple word searches
Basic Google searches consist of one or more words entered without any quotations or the use of special keywords.
Example:
The Google search engine has its own way around simple word searches, as above. Did you know that the following list of words is often ignored by the search engine anytime they are included in your search phrase? “a, about, an, and, are, as, at, be, by, from, how, I, in, is, it, of, on, or, that, the this, to, we, what, when, where, which, with” (These are known as stop words).
If you did know, then what have you been doing to ensure they are included to get a much-focussed result? The example above would mean that the google search engine will instead search for bitcoin, instead of the whole phrase as you intended. Below are some techniques that you could use to control the engine instead of unconsciously submitting to its search algorithms.
“+” searches
To force Google to include a common word, precede the search term with a plus (+) sign. Do not use a space between the plus sign and the search term.
For example, the following searches produce slightly different results (check the results listing plus the order of appearance):
Where is Egypt
+where is Egypt
“-" searches
To exclude a term from a search query, simply place a minus sign (-) before the term. Do not use a space between the minus sign and the search term. This technique can save you time if you typed a word in the search phrase but have decided to exclude it. For example, the following searches produce slightly different results:
Where is Kenya
-where is Kenya //excludes where from the result and searches for “is Kenya”
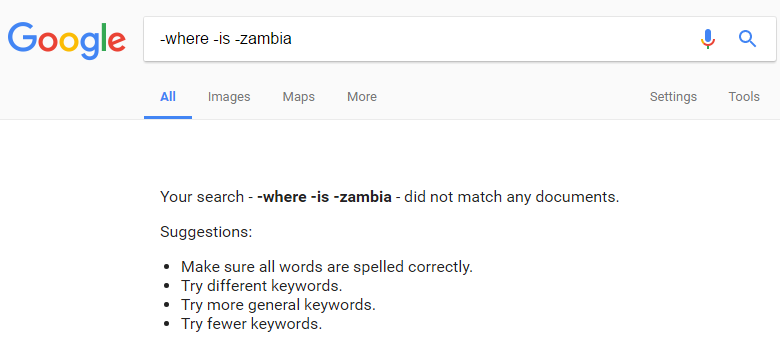
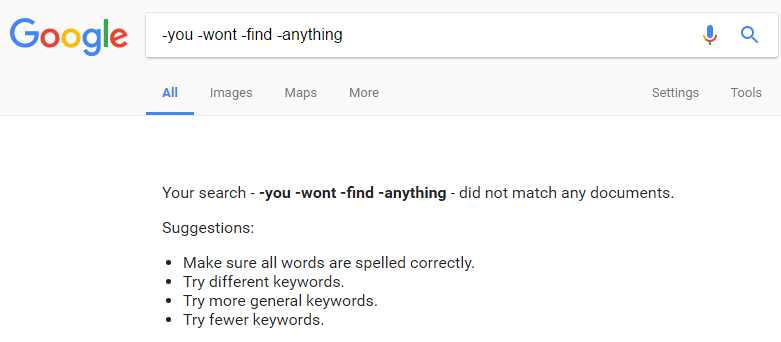
Try searching for -where -is -Zambia or –you –won’t –find –anything (they will produce the same results)
Phrase Searches
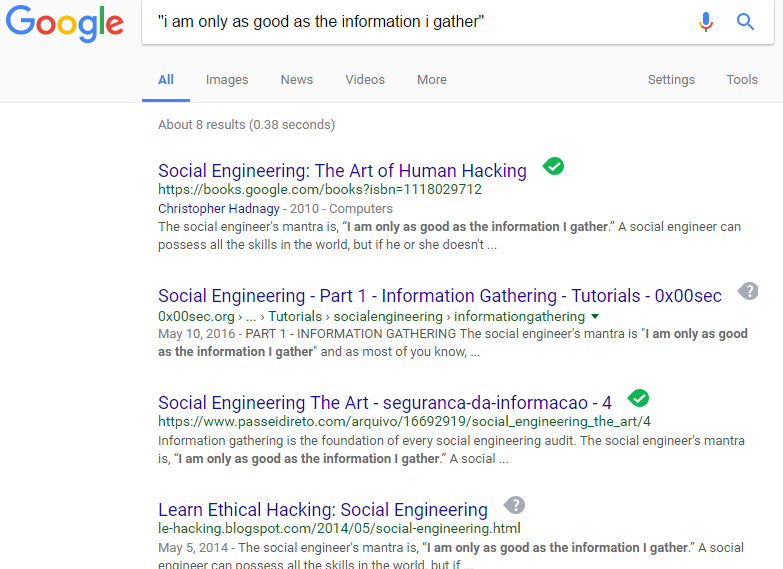
You might want to search for an article containing a particular phrase only. To do this, supply the phrase surrounded by double quotes.
Examples:
“I am only as good as the information I gather”
“I have a dream”
Mixed searches
Mixed searches can involve both phrases and individual terms. Example:
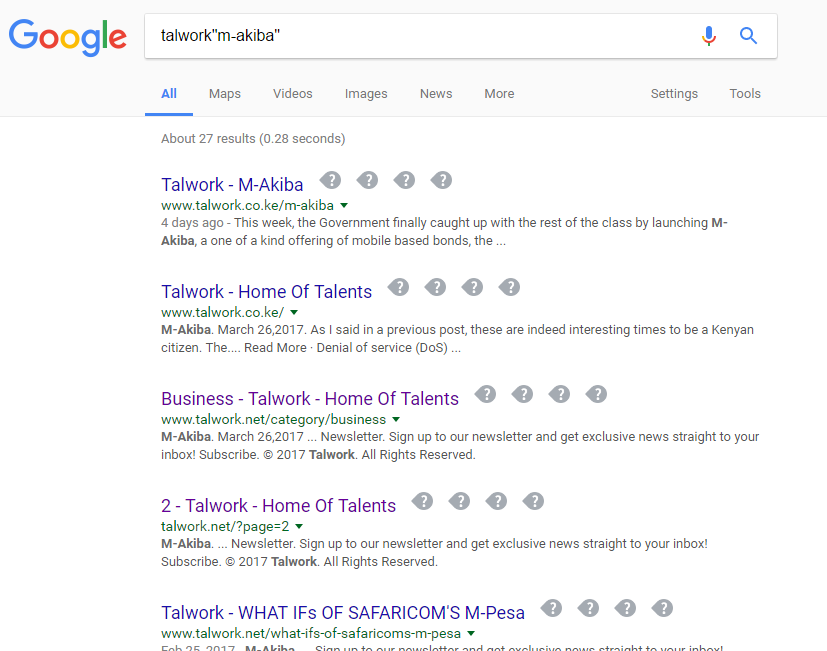
talwork"M-Akiba"
This search will only return results that include the phrase “M-Akiba” and the term talwork.
Google’s advanced operators
Google allows the use of certain operators to help refine searches. However, attention has to be given to the syntax. The basic format for their use is:
operator:search term
N/B: there is no space between the operator, the colon, and the search term. If space is used after a colon, Google will display an error message. If space is used before the colon, Google will use your intended operator as a search term. The advanced operators are described below.
site: find web pages on a specific website
This advanced operator instructs Google to restrict a search to a specific website or domain. When using this operator, an additional search argument is required.
Example:
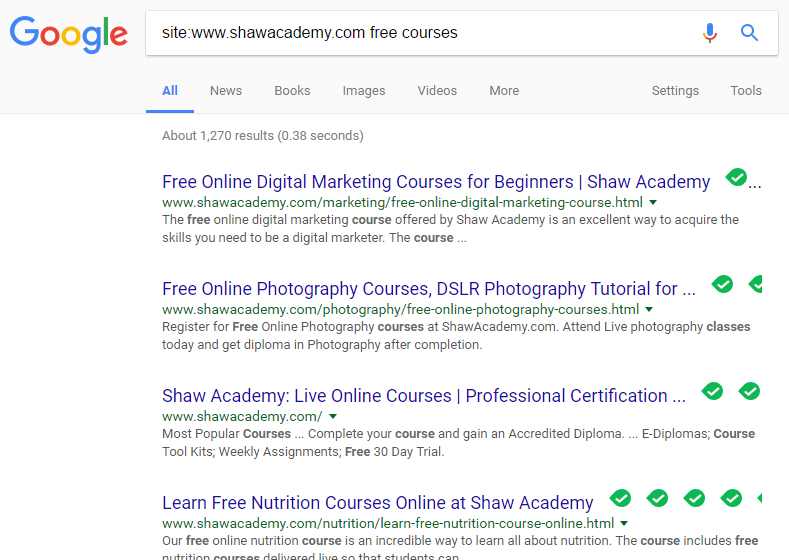
site:www.shawacademy.com free courses
This query will return results from shaw academy and other online platforms that include the term free courses anywhere on the page as below.
Info: Show Google’s Summary Information about a website
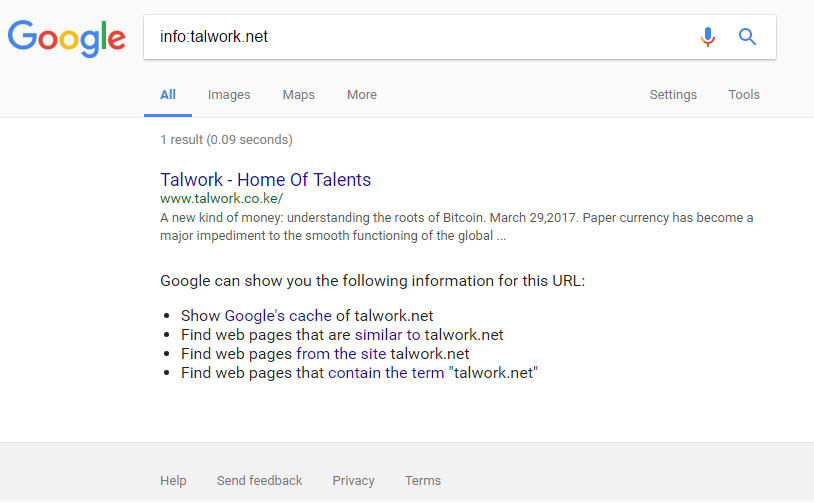
The info operator shows a site's summary information and links to other Google searches that might pertain to that site, as shown below. The parameter to this operator must be a valid URL or site name. You can achieve this same functionality by supplying a site name or URL as a search query.
Example: Info:Talwork.net
filetype: search only within files of a specific type.
This operator instructs Google to search only within the text of a particular file type. It requires an additional search argument.
Example:
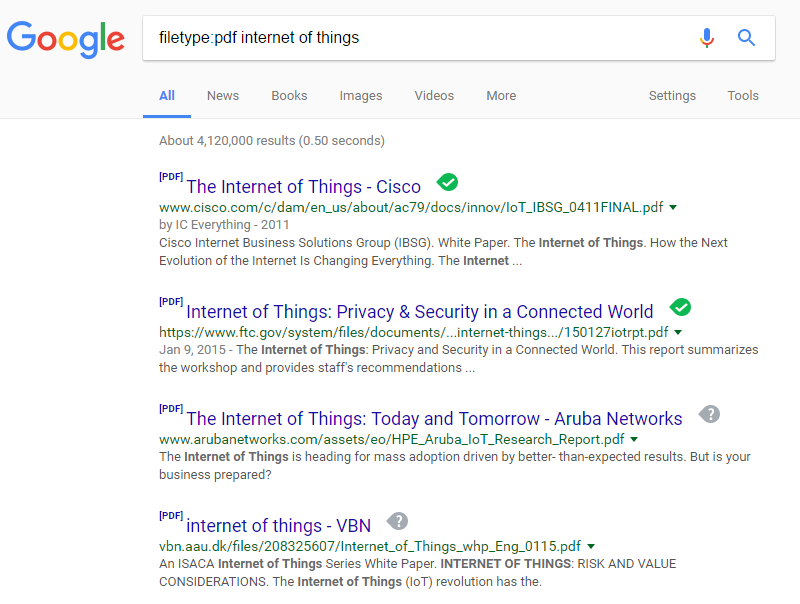
Filetype:pdf internet of things
This query searches for the word internet of things within adobe portable document format (pdf) documents.
There should be no period (.) before the file type and no space around the colon following the word “filetype”. It is important to note that Google only claims to be able to search within certain types of files.
The current list of files that Google can search for is listed in the filetype FAQ at: https://developers.google.com/search/docs/crawling-indexing/indexable-file-types As of this writing, Google can search within the following file types:
Adobe Portable Document Format (pdf), Adobe PostScript (ps), Lotus 1-2-3 (wk1, wk2, wk3, wk4, wk5, wki, wks, wku), Lotus WordPro (lwp), MacWrite (mw), Microsoft Excel (xls), Microsoft PowerPoint (ppt), Microsoft Word (doc), Microsoft Works (wks, wps, wdb), Microsoft Write (wri), Rich Text Format (rtf). Text (ans, txt)
link: search within links
A hyperlink is a selectable connection from one web page to another. These links often appear as underlined text but can appear as images, videos or any other type of multimedia content. This advanced operator instructs Google to search within hyperlinks for a search term. It requires no other search arguments.
Example:
link:www.apple.com
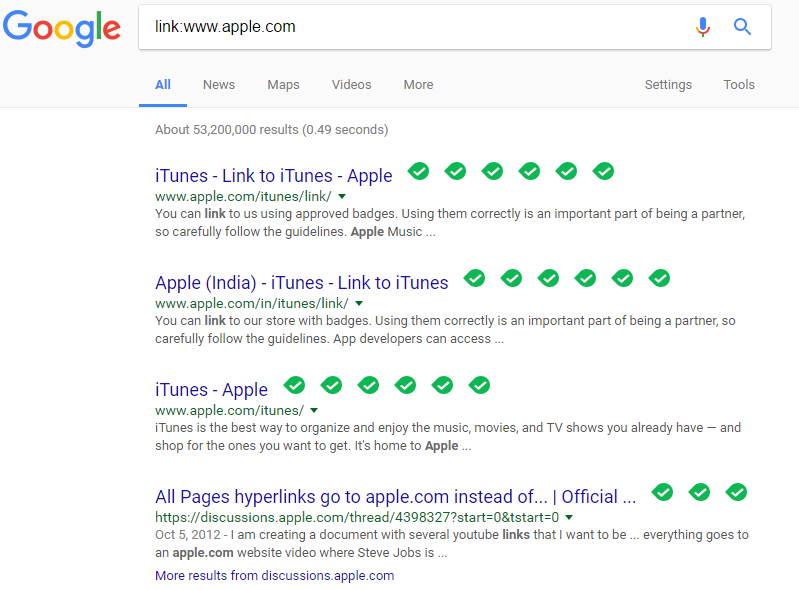
This query would display web pages that link to Apple.com’s main page. This special operator is somewhat limited because the link must appear exactly as entered in the search query.
cache: display Google’s cached version of a page
This operator displays the version of a web page as it appeared when Google crawled the site. It also gives you various options to view the text-only version of the page and the page’s source code. It requires no other search arguments.
Example:
cache:www.microsoft.com
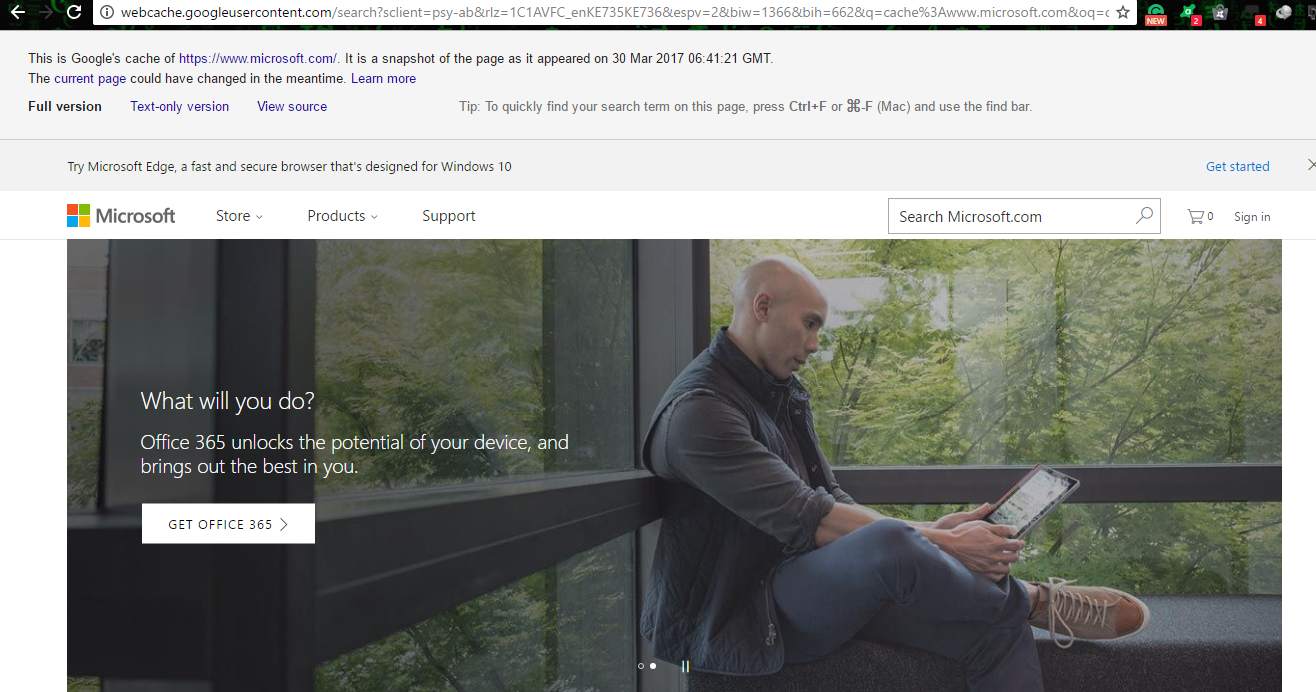
intitle: search within the title of a document
This operator instructs Google to search for a term within the title of a document. Most web browsers display a document's title on the browser window's top title bar.
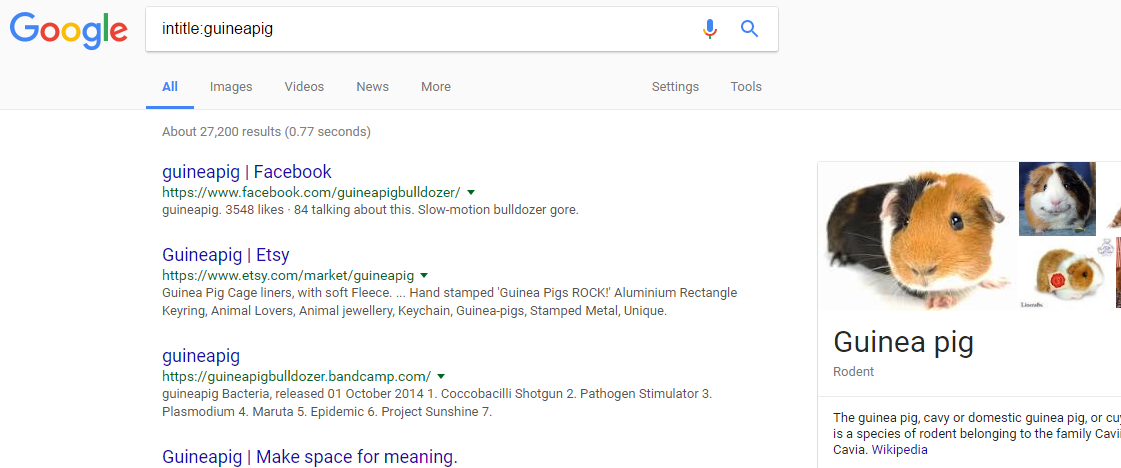
Example:
intitle:guineapig
This query would only display pages that contained the word ‘guineapig’ in the title.
A derivative of this operator, ‘allintitle’, works similarly.
Example:
allintitle:guineapig experimental
This query finds both the words ‘guineapig’ and ‘experimental’ in the title of a page. The ‘allintitle’ operator finds every subsequent word in the query only in the page's title.
inurl: search within the URL of a page
This operator instructs Google to search only within a document's URL or web address. This operator requires no other search arguments.
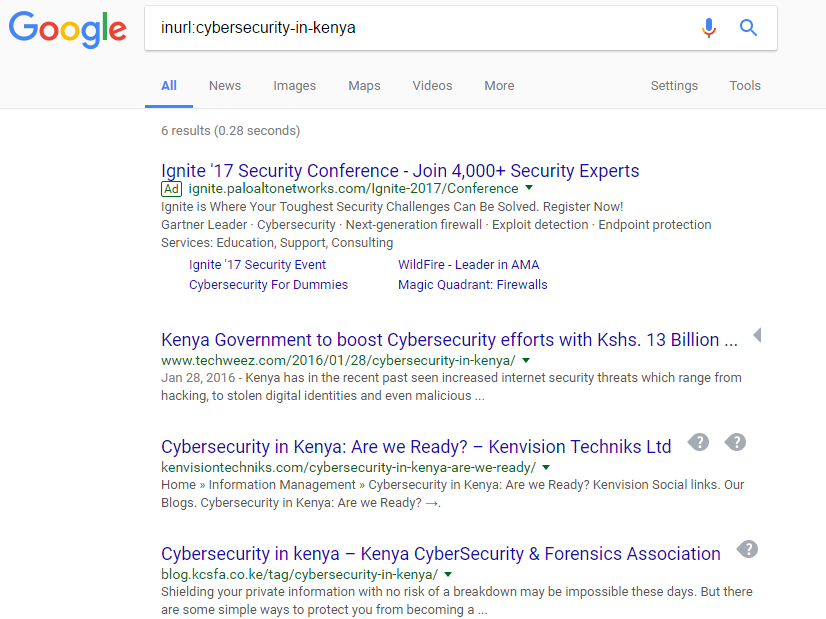
Example:
inurl:cybersecurity-in-kenya
This query would display pages with the word ‘cybersecurity-in-kenya’ inside the web address.
A derivative of this operator, ‘allinurl’, works similarly.
Example:
allinurl:Somaliland cyber
This query finds both the words ‘somaliland’ and ‘cyber’ in the URL of a page. The ‘allinurl’ operator instructs Google to find every subsequent word in the query only in the URL of the page.
Hackers' section
Do you want to become a hacker or improve your research skills? Below are tips and tricks to add to your toolbox.
Domain searches using the ‘site’ operator
The site operator can be expanded to search out entire domains. For example:
site:gov secret
This query searches every website in the .gov domain for the word ‘secret’. This is a great thing for journalists, and any other person, in general, can use this technique to find interesting stuff about a group of websites owned by organizations such as a government or non-profit organization. Hackers can also exploit this to find sensitive information.
Finding Directory listings (Index of)
Instead of the typical text-and-graphics mix generally associated with web pages, directory listings provide a list of files and directories in a browser window.
Directory listings are often placed on web servers purposely to allow visitors to browse and download files from a directory tree. Many times, however, directory listings are not intentional. A misconfigured web server may produce a directory listing if missing an index or main web page file.
Sometimes, directory listings are set up as temporary storage locations for files. Either way, there’s a good chance that an attacker may find something interesting inside a directory listing. Most directory listings begin with the phrase “Index of”, which also shows in the title. Using the query “intitle:index.of”, you may find pages with the term ‘index of’ in the document's title. Unfortunately, this query will return a large number of false positives. Several alternate queries, such as those below, provide more accurate results:
intitle:index.of "parent directory"
intitle:index.of name size
parentaldirectory:abcd
A search for parentaldirectory:apache results in the following
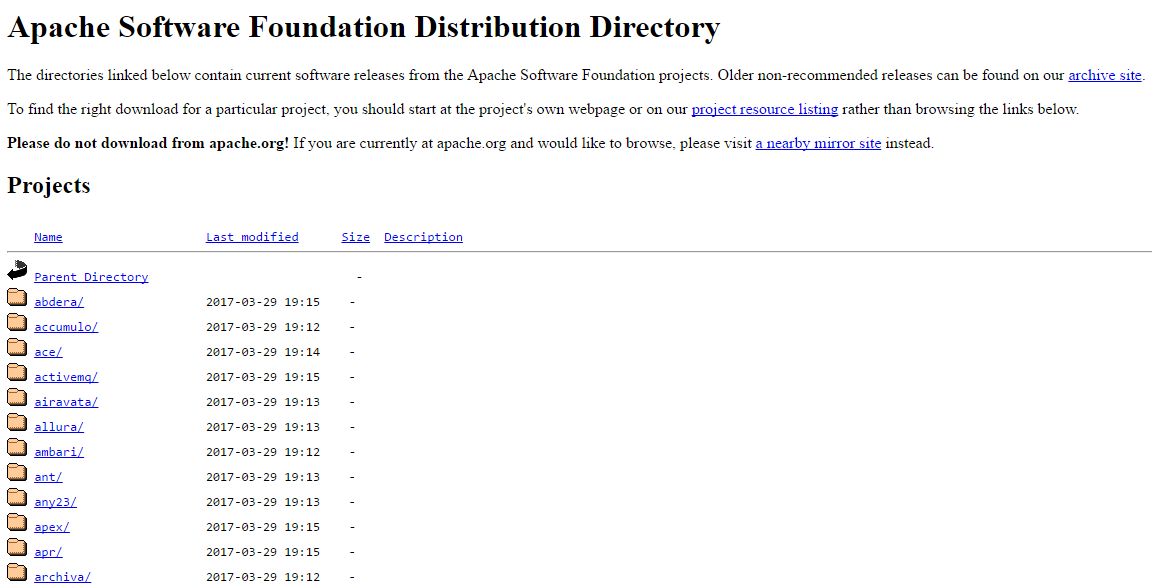
Versioning: Obtaining the Web Server Software / Version via directory listings
You can know the exact version of the web server software running on a server from Google without ever connecting to the target server under investigation. One method involves using the information provided in a directory listing. The directory listing includes the server software's name and the version.
intitle:index.of server.at
The above query focuses on the term “index of” in the title and “server at” appearing at the bottom of the directory listing. This type of query can additionally be pointed at a particular web server:
intitle:index.of server.at site:xyz.com
Using Google as a CGI scanner
Mercilessly searching out vulnerable programs on a server, the ‘CGI scanner’ or ‘web scanner’ has become one of the most indispensable tools in the world of web server hacking. However, they are not much appreciated by an advanced hacker.
To accomplish its task, these scanners must know what exactly to search for on a web server. In most cases, these tools are scanning web servers looking for vulnerable files or directories that may contain sample code or vulnerable files. Either way, the tools generally store these vulnerabilities in a file that is formatted like the following
/cgi-bin/cgiemail/uargg.txt
/random_banner/index.cgi
/random_banner/index.cgi
/cgi-bin/mailview.cgi
/cgi-bin/maillist.cgi
/cgi-bin/userreg.cgi
/iissamples/ISSamples/SQLQHit.asp
/iissamples/ISSamples/SQLQHit.asp
/SiteServer/admin/findvserver.asp
/scripts/cphost.dll
/cgi-bin/finger.cgi
The lines in a vulnerability file like the ones shown above can serve as a roadmap for a Google hacker. Each line can be broken down and used in either an ‘index.of’ or an ‘inurl’ search to find vulnerable targets.
A hacker can take sites returned from this Google search, apply a bit of hacker ‘magic’ and eventually get the broken ‘random_banner’ program to cough up any file on that web server, including the password file
using robots.txt file extension.
A robots.txt file provides critical information for search engine spiders that crawl the web. Before these bots (does anyone say the full word “robots” anymore?) access pages of a site, they check to see if a robots.txt file exists. Doing so makes crawling the web more efficient because the robots.txt file keeps the bots from accessing certain pages that the search engines should not index. simply add /robots.txt at the end of your search phrase.
Notice
All the nuggets and tricks shared in this article are for educational purposes only.