What is Web 3.0 ? The history and a look into the future
Published on April 19,2020
Florence has recently accomplished training as a beauty therapist at a highly reputed beauty college. With her are her credentials in the form of a certificate. She wishes to share her accomplishments with prospective employers. She, therefore, heads over to LinkedIn and updates her profile to reflect her academic and skills achievements. No sooner had she updated her LinkedIn profile than she received a congratulatory message from her friends on Twitter and a direct message from a beauty company through Facebook.
Her web agent from her portfolio website “francheflo.me” has just updated her on existing job vacancies in companies within a vicinity of 100Km, and salary ranges of Ksh.50K - 100K. Glassdoor web agent also updated francheflo WebClient on the average salaries of beauty therapists. The francheflo web agent was more than willing to push the notifications to Florence, adding her recommendations. All these came by because of a single update on a single page on the entire web.
Of course, such is not a reality today, but it’s what will be in the next five to ten years. As Bernes-Lee adds, “all this without needing artificial intelligence on the scale of 2001's Hal or Star Wars’ C-3PO… .” Instead, all that intelligence will reside within each web page. Let’s just call it a web full of meaning, or should we say semantics? Why don’t we just begin with the history of how we got here? How did it all begin?
In the beginning, there was an Idea.
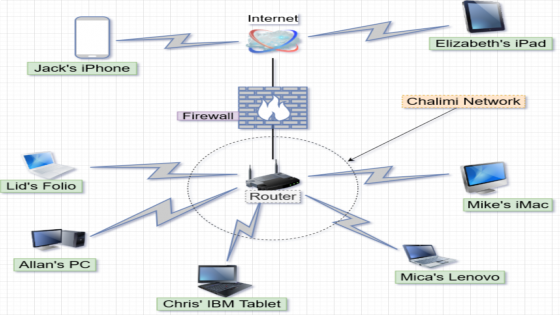
The idea of the Internet is rather mundane. What’s geeky about it are the technologies that make it. Let’s create five friends out of the air to aid us in elaborating on the idea. Allan Martin, Christopher Gilgamesh, Lidbary Lardof, Mike Saha, and Micah Josephus will take the stage. Take Allan’s, Chris’, Lidbary’s, Mike’s, and Micah’s computers and interconnect them via whatever means you have available; say an Ethernet cable, a wireless frequency channel, a fibre optic cable or rather, a psychic’s continuum vibrations of energy. So long as the five computers can exchange information through established protocols/rules that they all understand, you have an inter-network of computers, a.k.a, an internet (with a small letter ‘i’). Let’s call our internet ‘ChALiMi’ or ‘Chalimi’.
The Internet (with a capital ‘I’), as we know it, is of absolute resemblance to Chalimi. The only difference is the size. Although it began just as a nationwide internet for the USA in 1969 (in response to the Soviet’s Sputnik), it now spans the globe. Another Allan in Jamaica can still stay connected to another Chris in Dubai, Lidbary in China, Mike in the U.S, and Micah in Kenya. It doesn’t matter where one is geographically. With its span comes a great advantage, that of decentralization.
A copy of an Article of Association of a business owned by our five friends resides in their individual computers. If any copy is deleted or corrupted, there are still four left. Of course, a copy also exists at the regulator’s computer and another at the tax collector’s machine, and so the story goes. That alone was and still is the idea and vision of the Internet, a decentralized network of Computers where multiple copies of files reside. But then, the files could easily be synced among the computers when needed. There is also an open channel of communication between the five.
And then there was the Worldwide Web (WWW), or should we say Web 1.0?
“The World Wide Web went live, on my physical desktop in Geneva, Switzerland, in December 1990. It consisted of one Web site and one browser, which happened to be on the same computer. The simple setup demonstrated a profound concept; “that any person could share information with anyone else, anywhere.” Sir Tim Berners-Lee, the inventor of the World Wide Web.
The web is just a software system (the largest in the world) that runs on top of the Internet infrastructure. With it came technologies such as Hypertext Markup Language (HTML) for structuring pages to be shared over the system, Hypertext Transfer Protocol (HTTP) for sharing the web pages, and a browser to allow users to view/browse the pages. Ever since its invention, the Web has opened up new frontiers, and now it is an important business and information tool accessible from local and remote locations. In addition to serving up Web pages via HTTP, it also serves files via File Transfer Protocol (FTP), electronic resource management systems via Simple Network Management Protocol (SNMP), electronic mail via Post Office Protocol version 3 (POP3), Simple Mail Transfer Protocol (SMTP) and Internet Mail Access Protocol v4 (IMAP4), and data for wireless devices via Wireless Application Protocol(WAP), etc. These protocols are part of the Transmission Control Protocol/Internet Protocol (TCP/IP) suite.
Peeling back the mask, the beauty underneath is that some Vivian Nouakchott wandering about the continent of Australasia could easily publish her website (just a group of web pages) where she could frequently share her thoughts, so could a Jack Tolstoy sailing the Southern Ocean publish his portfolio as a trained data scientist for every prospective employer to view. A teacher named Elizabeth White could easily connect with her students in a virtual classroom via the web. It is an open space for everyone to publish and/or view any resource.
Say Hello to Web 2.0, applications_everywhere.com.
Along the way, something happened. There was a fundamental shift in how we use the Internet. Human beings saw it fit to put “themselves” into the web, a technology that only had dead files in it. Clearly stated, the web adopted a social, collaborative, and interactive philosophy. It marked the dawn of user-generated content. That alone is what distinguishes a web app from a website. As of now, I am not compelled to take any flight to Washington District of Columbia to feel the mood swings of Trump, I just head to Twitter, and it’s all there in his tweets. It is through the advent of social media platforms that you get to know a person from a computer network. Notable platforms are social blogs like WordPress and Tumblr; social networks like Facebook, Whatsapp, Twitter, LinkedIn, and Instagram; social news sites like Reddit and Digg; social wikis like Wikipedia, Wikiversity, and Wikibooks; social commerce like Amazon and eBay; etc. Notable mentions include Lughayangu (a platform where Africans preserve their dialects).
But as the web became interactive, so did the demand for technologies that brought interactivity to web pages. Technologies that would abstract away how the computers (servers and clients) interacted in the background and only exposed to the user what they sought after. Such technology was Asynchronous JavaScript and XML (AJAX). But this also meant that web developers had to upgrade their skill sets to include AJAX and related technologies. It’s interesting how technology can suddenly render your skill sets obsolete. You kind of have to upgrade as technologies upgrade, lest you are left behind. Such is the life of a web developer. As if these were not enough, there seems to be another evolution yet to take place in the webspace. Its impacts will be so profound that if you get it wrong as an implementer, then so will your life.
Karibu Web 3.0, 'I know what you mean'
Web 3.0, other than being called by many names such as the Semantic web and Web of Data, has also been confused by other terms like Linked Data which refer to other related technologies. But what is it all about anyway?
What exists today as the web (1.0 and 2.0) is a publishing medium for everybody. What it is not, however, is smart. FYI ‘smart’ means machine-like or for machines. There is a difference between information for human consumption and information for machines. The former are sentences that make sense to Tom, Dick, and Harry. However, the latter ought to be structured in a way C-P3O can understand.
Web 3.0, or the Semantic web, is all about linking explicit data on the world wide web in a machine-readable fashion. What I mentioned in the introductory paragraph as web agents are the machines that I talk of. Although being software-based and more appropriately termed AI systems, this might prove otherwise. Berners-Lee et al. (2001) state that for the semantic web to function, computers must have access to structured collections of information and sets of inference rules that they can use to conduct automated reasoning. Since the early 21st century, research has been ongoing on these technologies. The paper adds that the challenge of the Semantic Web is to provide a language that expresses both data and rules for reasoning about the data, L and that allows rules from any existing knowledge-representation system to be exported onto the Web.
Do you get it? Take Dorian’s government data, e.g. her criminal records, social data from social media e.g. her birthday, commercial data like the company where she works, and scientific data like her COVID-19 status from African COVID-19, and then bundle all of them into a format that is machine crawlable. And there you have it.
Since all these data sets are machine-readable, they need not be contained in a single database or system. You can scatter them all over the web in different web apps and sites however you like. The web agent will crawl them for you and then present them as if they were one. As if they existed in one place. It will just have to search for meaning from those websites. “This Dorian is ...and was born in...and worked at...etc.”
On search engines
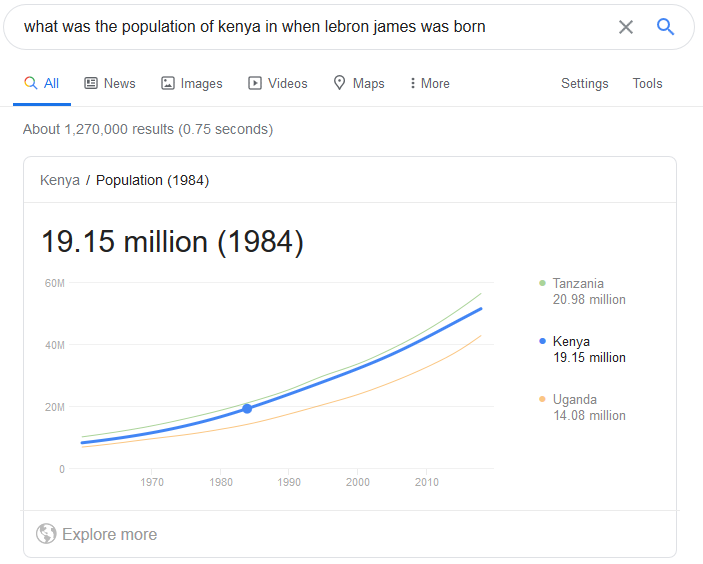
Existing search engines only look for ‘data that contains. If you search for “Palm Sunday” via Google, Bing, Yahoo, or DuckDuckGo, the respective search engine crawlers will simply look for sets containing the words “Palm Sunday” and then return the addresses of the sites that contained the words. I have to say, it’s way more than that, but that is the principle upon which they work. There have been recent upgrades to engines like Google to enable it to “understand the meaning of the words ‘Palm Sunday’.” It is, however, too early. Try searching for “what was the population of Kenya when Lebron James was born” you will be surprised to see the above result. A promising future perhaps?
Technologies driving Web 3.0
Disclaimer: I wish not to make this article fully geeky. If you want to learn the technologies from the geek who created them, head over to The World Wide Web Consortium (W3C) definitions of the technologies. I will simply mention a few. A web full of meaning requires a flexible data model for structuring the data. Models include Resource Description Format (RDF), the old XML, and the count in schema.org. A distributed query language is also required for querying the data from varied sources. They include the recursive SPARQL Protocol, RDF Query Language (SPARQL), and a Web Ontology Language (OWL). Halt.
Conclusion.
The future is full of targeted semantic search, data browsing, and automated web agents, just to mention a few. Application areas such as data integration and virtualization, Business Intelligence, and Large knowledge bases will also arise. As WWW is to web pages, the Semantic web is to Data. The web will evolve. The developer must hone his skills. But to what end is all this? Maybe this?