How to access the dark web - deep sea exploration
Published on April 24,2017

From the analogy illustrated in the diagram, the deep web is below the ocean's surface. The dark web, however, is at the bottom of the ocean.
Deep sea exploration or just sea diving has it that special attires have to be put on before you endeavour into this part of the world. The same applies to computer deep-web diving.
Special tools, e.g. software and wetware (knowledge brain), are required for a successful exploration. Otherwise, you will drown. Who knows which form of drowning you will experience (you might have drowned in sites such as Silkroad -had it still existed, and I tell you, the crocodiles would have preserved your dead body for future complicated devour).
Diving through the deep web is not for every Tom, Dick, and Harry. You need to be a Snowden at least at the start or rather when already there. I would highly advise that you read the first article on the dark web before proceeding with this.
Difference between normal web and dark web
You might be wondering why you need special software, e.g. browser, yet you have google chrome. Allow me to shed some light on this before you are made a little Snowden.
Traditional search engines such as Google or Bing often use “web crawlers” to access websites on the Surface Web. This crawling process searches the web and gathers websites that the search engines can then catalogue and index.
Consider the image below.
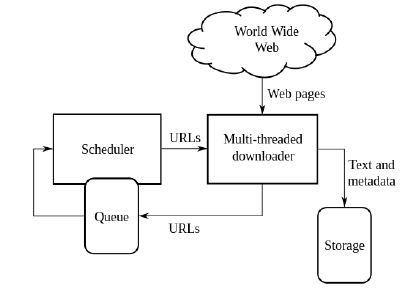
However, content on the Deep (and Dark) Web may not be caught by web crawlers (and subsequently indexed by traditional search engines). Search engine crawlers often do not pick up most resources, including:
- Dynamic content: dynamic pages which are returned in response to a submitted query or accessed only through a form.
- Unlinked content: pages which are not linked to other pages (i.e. backlinks or inlinks)
- Private Web: sites that require registration and login to access even a bit of information
- Limited access content: sites that limit access to their pages (in a technical way)
- Scripted content: pages that are only accessible through links produced in scripts such as JavaScript)
- Non-HTML/text content: textual content encoded in multimedia files
- Text content using the Gopher protocol and files hosted on irregular FTP
The above may happen for several reasons, including that the documents on the deep (or dark) web may be unstructured, unlinked, or temporary content.
You might also consider your security while on these networks. That’s exactly why special pieces of stuff are needed, though not many.
Tools needed to access the dark web.
The first thing you would want to do is download Tor (The Onion Router) browser.
Initially released as The Onion Routing project in 2002, Tor was originally created by the U.S. Naval Research Laboratory as a tool for anonymously communicating online.
‘Onion’ from the name refers to the proxy chains it uses. They are layered just like the stem of an onion.
Tor “refers to the software you install on your computer to run Tor and the network of computers that manages Tor connections.
Tor’s users connect to websites through a series of virtual tunnels (a proxy chain for the network enthusiasts) rather than making a direct connection, thus allowing both organisations and individuals to share information over public networks without compromising their privacy.
Users route (direct to the best path) their web traffic through other users’ computers such that the traffic cannot be traced to the original user.
Tor essentially establishes layers (like layers of an onion) and routes traffic through those layers to conceal users’ identities.
To get from layer to layer, Tor has established relays on computers worldwide through which information passes.
Information is encrypted (jumbled up using a special technique, e.g. advanced encryption standard (AES)) between relays and all Tor traffic passes through at least three relays before it reaches its destination.
The final relay is called the exit relay, and the IP address of this relay is viewed as the source of the Tor traffic.
When using Tor software, users’ IP addresses remain hidden. As such, it appears that the connection to any given website comes from the IP address of a Tor exit relay, which can be anywhere in the world. It’s, therefore, a good choice even for the privacy-conscious.
After downloading the browser software, install it (the installation wizard is a graphical user interface (GUI) that is simple to use).
A successful setup should bring a connect prompt which you should click. Wait for the browser to establish a secure connection through the proxy chain; if all goes well, you should see a page similar to this in the browser window.
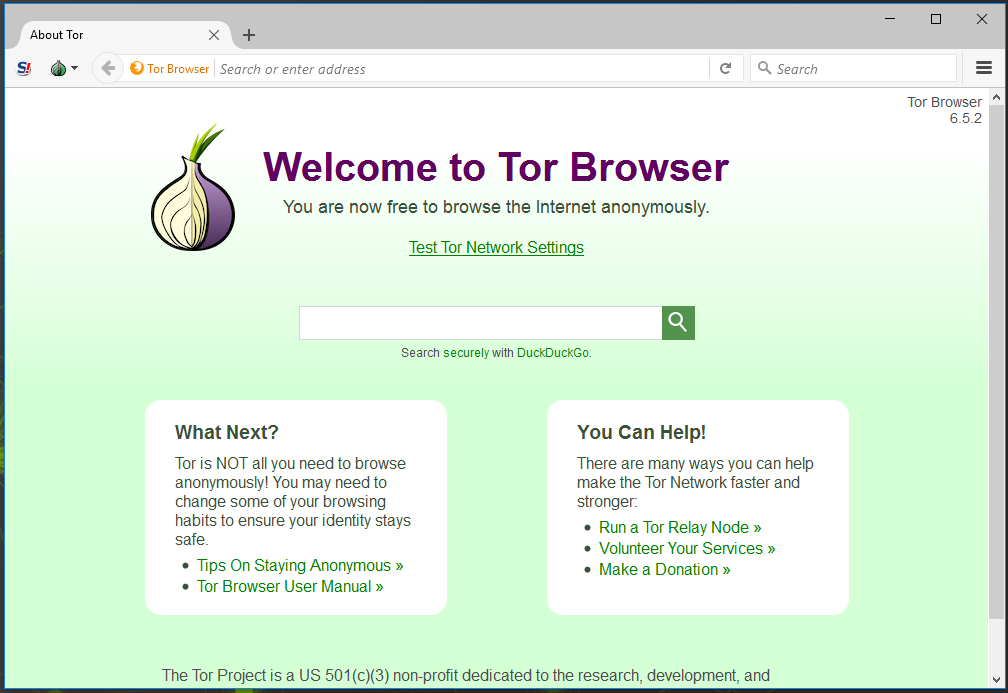
Accessing and navigating the dark web
Information on the Deep Web includes content on private intranets (internal networks such as those at corporations, government agencies, or universities), commercial databases like Lexis-Nexis or Westlaw, or sites that produce content via search queries or forms. Serious illegal contents are also available.
You need to know what is next after a successful connection.
You may want to hop to forums that often provide links to sites within the Dark Web.
Reddit is an example. It provides a public platform for Dark Web users to discuss different aspects of Tor. It is not encrypted or anonymous, as users who wish to engage in forum discussion must create an account. Just type www.reddit.com in the search bar, and Create an account to join the community. then browse through like DarkNetMarkets, DeepWeb or Tor.
To use a more secure form of communication, you may utilise email, web chats, or personal messaging hosted on Tor.
Several anonymous, real-time chat rooms, such as The Hub and OnionChat, are hosted on Tor. Feeds are often organised by topic. You may find the right directories from the Reddit community or http://chatrapi7fkbzczr.onion/.
You might also consider Tor Messenger for personal messaging.
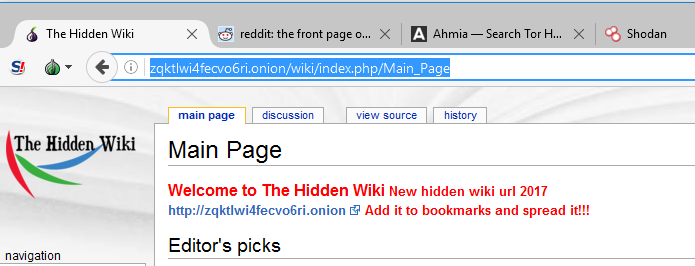
The shortest way to access numerous deep web and darknet pages is through directories such as the “Hidden Wiki,” which organises sites by category, similar to Wikipedia.
Finding the hidden wiki page, however, is often problematic. The page URL changes after some days or months to prevent seizures by agents like those that seized the ‘Silkroad’ website.
As of now, the current URL is at http://zqktlwi4fecvo6ri.onion/wiki/index.php/Main_Page. I would recommend you bookmark the page after successfully opening it.
In addition to the above techniques, individuals can search the Dark Web with special search engines. These search engines may be broad, searching across the Deep Web, or they may be more specific.
For instance, Ahmia, an example of a broader search engine, is one that indexes, searches and catalogues content published on Tor Hidden Services.
Others include; business.com for business-related stuff, scirus for scientific information only. Some, like Grams, are for illegal activities, and I would not encourage you to visit them.
An advanced individual might consider Shodan. Shodan lets the user find specific types of computers connected to the internet using various filters, Routers, servers, traffic lights, security cameras, home heating systems, Control systems for water parks, gas stations, water plants, power grids, nuclear power plants and particle-accelerating cyclotrons.
It is a search engine majorly for the Internet of things.
An onion site such as the hidden wiki may load very slowly for obvious reasons (it is hidden in a layer of networks).
These hidden sites on the Tor network can be distinguished by looking at the web page's title. They often have an onion icon beside them, such as below for the Hidden wiki.
Conclusion
I would say that there is no guaranteed anonymity online. Even if you are using Tor, for that matter.
Consider this. In February 2017, hackers purportedly affiliated with Anonymous took down Freedom Hosting II—a website hosting provider on the dark web that was stood up after the original Freedom Hosting was shut down in 2013.
Hackers claimed that over 50% of the content on Freedom Hosting was related to child pornography. Website data were dumped, some of which may now identify users of these sites.
You might want to consider buffering your security. This article may provide a lead.
Albeit in an information age where there is right to information, information misused is often dangerous and will scar you.
I advocate for the correct usage of the information provided hereby. It was simply for educational purposes only. If you feel that anything is left out or you need an article about a related topic, fail not to leave a comment. You are my priority.